音声認識に挑戦してみましょう。
・Juliusはラズパイでも使用可能なオープンソースの音声認識エンジンです。(julius公式ページ)クラウド型ではないので、インターネットにつながなくても動作します。オープンライセンスなので個人利用はもちろん、商用でも無償で利用することができます。
・べゼリー音声対話キットに付属しているSDカードには2016年9月21日にリリースされたDictation version 4.4がインストールされています。
事前準備
・マイクとスピーカーの両方を使いますので、それぞれちゃんと機能していることを事前にご確認ください。

音声キーワード認識サンプル(sample_julius1.py)
・事前にユーザーが登録したキーワードを認識させます。決められた言葉にしか反応しませんが、高い精度で認識することができます。
実行方法
・2つの手順が必要です。まずジュリアス(音声キーワード認識版)を起動します。
$ ./boot_julius.sh
・起動するまで数秒待ちます。
・続いて、juliusからデータを受け取って表示するpythonのプログラムを実行します。
$ python sample_julius1.py
・マイクに向かって「こんにちは」「ありがとう」などと喋ってみてください。画面に「昼の挨拶」「感謝」など「話者の意図」が表示されたら成功です。
ソースプログラム
#!/usr/bin/python
# -*- coding: utf-8 -*-
# 音声対話デモ
# for Bezelie Edgar
# for Raspberry Pi
# by Jun Toyoda (Team Bezelie)
# from Aug15th2017
from time import sleep # ウェイト処理
import subprocess # 外部プロセスを実行するモジュール
import bezelie # べゼリー専用モジュール
import socket # ソケット通信モジュール
import select # 待機モジュール
import json # jsonファイルを扱うモジュール
import csv # CSVファイルを扱うモジュール
import sys # python終了sys.exit()のために必要
import re # 正規表現モジュール
jsonFile = "/home/pi/bezelie/edgar/data_chat.json" # 設定ファイル
ttsFile = "/home/pi/bezelie/edgar/exec_openJTalk.sh" # 音声合成
# 設定ファイルの読み込み
f = open (jsonFile,'r')
jDict = json.load(f)
mic = jDict['data0'][0]['mic'] # マイク感度。62が最大値。
vol = jDict['data0'][0]['vol'] # スピーカー音量。
# 変数の初期化
muteTime = 1 # 音声入力を無視する時間
bufferSize = 256 # 受信するデータの最大バイト。2の倍数が望ましい。
# 関数
def socket_buffer_clear():
while True:
rlist, _, _ = select.select([client], [], [], 1)
if len(rlist) > 0:
dummy_buffer = client.recv(bufferSize)
else:
break
# サーボの初期化
bez = bezelie.Control() # べゼリー操作インスタンスの生成
bez.moveCenter() # サーボの回転位置をトリム値に合わせる
# TCPクライアントを作成しJuliusサーバーに接続する
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
enabled_julius = False
for count in range(3):
try:
client.connect(('localhost', 10500))
# client.connect(('10.0.0.1', 10500)) # Juliusサーバーに接続
enabled_julius = True
break
except socket.error, e:
# print 'failed socket connect. retry'
pass
if enabled_julius == False:
print 'Could not find Julius'
sys.exit(1)
# メインループ
def main():
try:
print '音声認識開始'
subprocess.call('amixer cset numid=1 '+vol+'% -q', shell=True) # スピーカー音量
subprocess.call('sudo amixer -q sset Mic 0 -c 0', shell=True) # 自分の声を認識してしまわないように$
subprocess.call("sh "+ttsFile+" こんにちわ", shell=True)
subprocess.call('sudo amixer sset Mic '+mic+' -c 0 -q', shell=True) # マイク感受性
data = ""
socket_buffer_clear()
while True:
if "</RECOGOUT>\n." in data: # RECOGOUTツリーの最終行を見つけたら以下の処理を行う
data = re.search(r'WORD\S+', data) # \s
keyword = data.group().replace("WORD=","").replace("\"","")
subprocess.call('sudo amixer -q sset Mic 0 -c 0', shell=True) # 自分の声を認識してしまわないよ$
print keyword
subprocess.call("sh "+ttsFile+" "+keyword, shell=True)
subprocess.call('sudo amixer -q sset Mic '+mic+' -c 0', shell=True) # マイク感受性を元に戻す
socket_buffer_clear()
data = "" # 認識終了したのでデータをリセットする
else:
data = data + client.recv(bufferSize) # Juliusサーバーから受信
# /RECOGOUTに達するまで受信データを追加していく
except KeyboardInterrupt: # CTRL+Cで終了
client.close()
bez.moveCenter()
sys.exit(0)
if __name__ == "__main__":
main()
sys.exit(0)
終了方法
・pythonプログラムの「sample_julius1.py」は、いつものようにコントロールキー+Cキーで停止します。
・しかしjuliusはバックグラウンドで動き続けているので、これだけでは止まってはくれません。juliusを停止させるのは、ちょっと面倒です。
・まずは下記のように打ち込んで、juliusのプロセスIDを調べます。
$ check_running.sh
・例えば以下のように表示されたとすると、juliusのプロセスIDは3923だということがわかります。
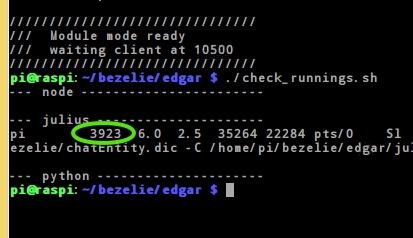
・プロセスIDが3923のプロセスを停止するには、以下のようにうちみます。
$ sudo kill 3923
・これで停止できたはずです。心配ならもういちどcheck_running.shを実行して、juliusが表示されないことを確認しましょう。
自然言語認識サンプル(sample_juliusNL1.py)
・単語だけでなく、普通に喋った言葉をjuliusが文字に変換してくれます。言語モデルの学習など手をかければ精度は上がるはずですが、初期状態ではよく使う表現しか認識してくれません。
実行方法
・やはり2つの手順が必要です。まずジュリアス(自然言語認識版)を起動します。
$ ./boot_juliusNL.sh
・数秒待ってから、juliusからデータを受け取って表示するpythonのプログラムを起動します。
$ python sample_juliusNL1.py
・好きな言葉を喋ってみてください。ありふれた言葉以外は、正しく認識されないと思います。
ソースプログラム
#!/usr/bin/python
# -*- coding: utf-8 -*-
# Julius音声認識(自然言語版)サンプル
# for Bezelie Edgar
# for Raspberry Pi
# by Jun Toyoda (Team Bezelie)
# from Aug15th2017
from time import sleep # ウェイト処理
import subprocess # 外部プロセスを実行するモジュール
import bezelie # べゼリー専用モジュール
import socket # ソケット通信モジュール
import select # 待機モジュール
import json # jsonファイルを扱うモジュール
import csv # CSVファイルを扱うモジュール
import sys # python終了sys.exit()のために必要
import re # 正規表現モジュール
import xml.etree.ElementTree as ET # XMLエレメンタルツリー変換モジュール
jsonFile = "/home/pi/bezelie/edgar/data_chat.json" # 設定ファイル
ttsFile = "/home/pi/bezelie/edgar/exec_openJTalk.sh" # 音声合成
# 設定ファイルの読み込み
f = open (jsonFile,'r')
jDict = json.load(f)
mic = jDict['data0'][0]['mic'] # マイク感度。62が最大値。
vol = jDict['data0'][0]['vol'] # スピーカー音量。
# 変数の初期化
muteTime = 1 # 音声入力を無視する時間
bufferSize = 256 # 受信するデータの最大バイト。2の倍数が望ましい。
# 関数
def socket_buffer_clear():
while True:
rlist, _, _ = select.select([client], [], [], 1)
if len(rlist) > 0:
dummy_buffer = client.recv(bufferSize)
else:
break
# TCPクライアントを作成しJuliusサーバーに接続する
client = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
enabled_julius = False
for count in range(3):
try:
client.connect(('localhost', 10500))
# client.connect(('10.0.0.1', 10500)) # Juliusサーバーに接続
enabled_julius = True
break
except socket.error, e:
# print 'failed socket connect. retry'
pass
if enabled_julius == False:
print 'Juliusが起動していないようです'
sys.exit(1)
# メインループ
def main():
try:
subprocess.call('amixer cset numid=1 '+vol+'% -q', shell=True) # スピーカー音量
subprocess.call('sudo amixer -q sset Mic 0 -c 0', shell=True) # 自分の声を認識してしまわない $
subprocess.call("sh "+ttsFile+" 音声認識開始", shell=True)
sleep (muteTime)
subprocess.call('sudo amixer sset Mic '+mic+' -c 0 -q', shell=True) # マイク感受性
socket_buffer_clear()
print 'ー何か喋ってくださいー'
data = ""
while True:
if "</RECOGOUT>\n." in data: # RECOGOUTツリーの最終行を見つけたら以下の処理を行う
try:
# dataから必要部分だけ抽出し、かつエラーの原因になる文字列を削除する。
data = data[data.find("<RECOGOUT>"):].replace("\n.", "").replace("</s>","").replace("<s>","")
# fromstringはXML文字列からコンテナオブジェクトであるElement型に直接変換する。
root = ET.fromstring('<?xml version="1.0" encoding="utf-8" ?>\n' + data)
keyword = ""
for whypo in root.findall("./SHYPO/WHYPO"):
keyword = keyword + whypo.get("WORD")
subprocess.call('sudo amixer -q sset Mic 0 -c 0', shell=True) # 自分の声を認識してしま$
print keyword
subprocess.call("sh "+ttsFile+" "+keyword, shell=True)
sleep (muteTime)
socket_buffer_clear()
subprocess.call('sudo amixer -q sset Mic '+mic+' -c 0', shell=True) # マイク感受性を元に戻す
print "ー何か喋ってくださいー"
except:
print "----- except -----"
data = "" # 認識終了したのでデータをリセットする
else:
data = data + client.recv(bufferSize) # Juliusサーバーから受信
# /RECOGOUTに達するまで受信データを追加していく
except KeyboardInterrupt: # CTRL+Cで終了
client.close()
sys.exit(0)
if __name__ == "__main__":
main()
sys.exit(0)
解説
・18行目でimportしているElementTreeは、juliusから送られてきたxmlを解釈するために利用しているモジュールです。